Accurate locomotion mode recognition enables assistive devices to provide proactive support for individuals with mobility impairments. Combining inertial measurement units (IMUs), which capture body kinematics, with egocentric vision, which provides environmental context, offers a promising approach. In practice, existing public datasets for locomotion mode recognition are limited to healthy subjects, lack frame-level labels necessary for precise recognition, or feature a limited set of tasks.
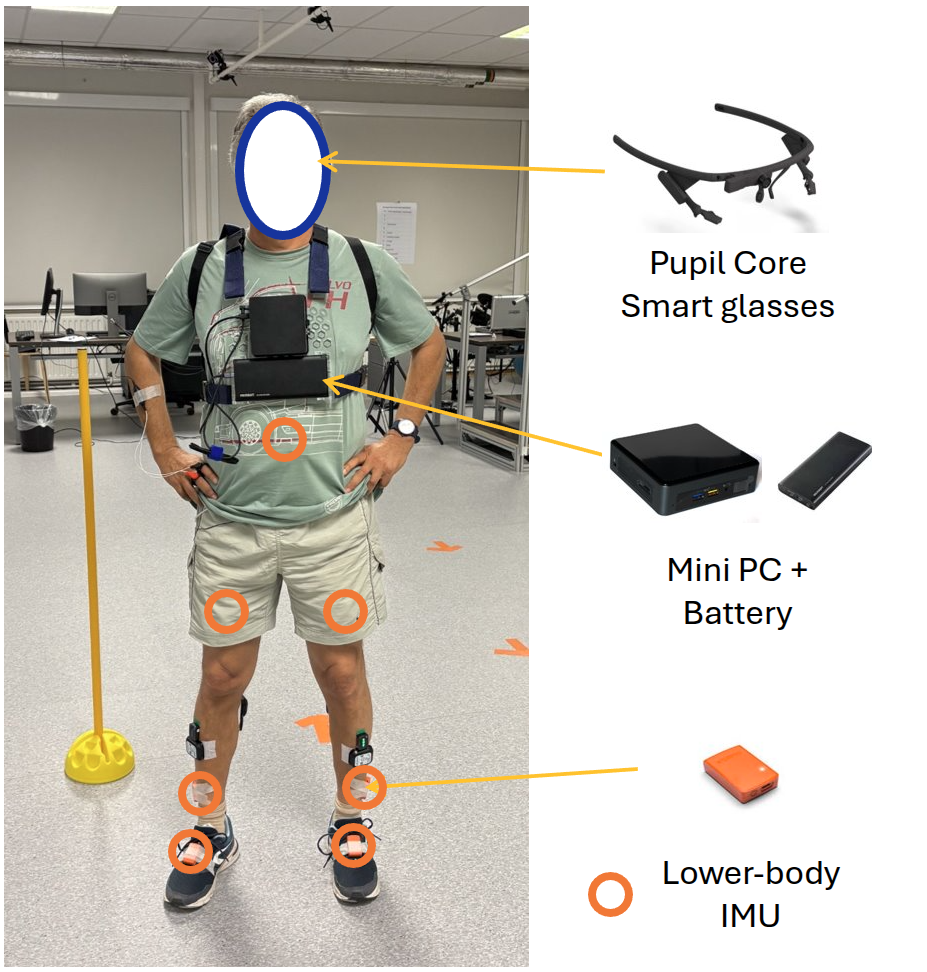
We present RevalExo, a dataset spanning healthy (older adults without mobility impairments) and clinical populations (with limited mobility) for locomotion mode recognition. The dataset includes synchronized egocentric video and lower-body IMU recordings from 13 participants (7 healthy older adults, 6 stroke survivors), and additional lower-body IMU-only recordings from 14 participants (4 stroke survivors, 10 older adults with probable sarcopenia).
We benchmark three challenges: unimodal and multimodal locomotion mode recognition across multiple prediction horizons, cross-population generalization, and vision-guided knowledge transfer. Our benchmarks confirm the benefits of multimodal fusion while revealing a substantial gap between general recognition (~93% F1) and recognition during transitions (~71% F1), as well as challenges in cross-population generalization and cross-modal transfer. Reliable recognition during transitions is critical for real-world assistive control and warrants further research.